Item Templates
As software developers who spend a large majority of our time in front of our IDE, it makes sense to optimize it’s settings to meet our specif needs. Changing just a few small things can have dramatic time savings over the long run if we are constantly having to do them over and over again. I am going to primarily focus on Visual Studio item templates. Every time you hit shift+alt+c to add a new class file or right click on a project and choose “Add->New Item…” this gives you the ability to select a pre-canned/starter file. These files contain the same boring and repetitive skeleton code to get that type of item started. Imagine having to type out all your usings, namespace, and class declarations every time you need to create a new class. Item templates are a great productivity booster!
Ya, And?
So you are probably saying to yourself, so what, every one knows about these and have been using them forever. What if you don’t like the pre-canned ones? What if you love them and wish they were just slightly different? What if you wanted your own custom, perhaps multi-file item templates? I am sure many of you have downloaded other item templates that come with extensions or even as standalone templates from the Visual Studio Gallery. Today I am going to show you how you can modify existing item templates or create your own.
If Only It Had…
If I had to guess, I would venture to say that, the most common item template for a C# developer is the Class item template. One way we can possibly improve on this template is to make the class public. I am almost always having to do this manually, and it bothers me. You could also make it default to internal if you feel safer that way.
OK, lets enhance the default one. The default class item template is installed at “C:\Program Files (x86)\Microsoft Visual Studio 12.0\Common7\IDE\ItemTemplates\CSharp\Code\1033\Class”, the location should only vary based on the Visual Studio version you are using, I currently am using 2013. Inside of this folder are two files Class.cs and Class.vstemplate. The .cs file is a template filled with parameters that Visual Studio will replace when you choose it through adding a new item. This is the main file we care about, here we can add the public key word in front of class. Lets say we want a default public constructor as well. Lets also remove the use of System.Threading.Tasks using statement, since 90% of the time I don’t need that. Now we end up with a file that looks like this:
using System;
using System.Collections.Generic;
$if$ ($targetframeworkversion$ >= 3.5)using System.Linq;
$endif$using System.Text;
namespace $rootnamespace$
{
public class $safeitemrootname$
{
public $safeitemrootname$()
{
}
}
}
(To edit this file you need admin rights, also if you try and use it after editing, it may not take your changes right away, as VS does some caching of these files. Some of the times I had to copy the .cs file into “C:\Program Files (x86)\Microsoft Visual Studio 12.0\Common7\IDE\ItemTemplatesCache\CSharp\Code\1033\Class” to see it immediately, I am not sure when VS updates this cache location on its own.)
Now when we add a new class, we get the following:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace ClassLibrary1
{
public class MyNewClass
{
public MyNewClass()
{
}
}
}
In the template file, you will notice all the $parameter$’s that are filled in by VS when adding a new item. A list of all the ones available can be found at https://msdn.microsoft.com/en-us/library/eehb4faa.aspx. You can do all kinds of fun things with these. Some companies I have worked for have headers at the top of all their files. These headers have things like copy write information, the date and time that the file was created, and the user who created the file. All this stuff can be pre-populated using some of the available parameters.
You Promised Multiple Files!
So far I have shown you how the template files can be created and how to edit existing ones. What if you love the current ones and want to create your own additional ones? Now I know there are even cooler things that can be done with scaffolding, that are much more complex, but I am not going to get into those here.
I often find myself creating an entity then a repository for that entity along with an interface for the repository. My entity always has things like an Id that I can include in a custom item template. My repository is always named EntityNameRepository and implements IEntityNameRepository. Some times I also need an angular service and MVC controller for that entity as well. These types of scenarios are a perfect use cases for item templates. Since I already demonstrated how to work on the template file, here I will show you how to create a new item template package with multiple files.
To start, open up any type of new project in visual studio or existing one, I used a class library. Fill out all the template files you will want, in my case I created two files one called Class.cs and the other Repository.cs, don’t worry their names will be overridden later on. After you have your skeleton code and $parameters$ in place you are ready to export. In Visual Studio clicking File -> Export Template will bring up the Export Template Wizard.
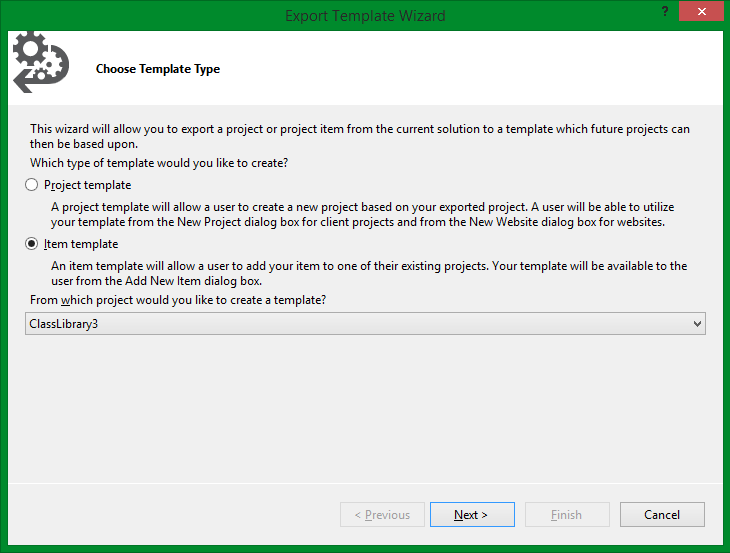
Select “Item template” and from which project you want to export from. Clicking “Next” will take you to a page in which you can select the file you want as a template, unfortunately you can only pick one from this dialog, don’t worry we just have to manually add the others. After selecting a file and clicking next you will be able to select what assemblies you want included when adding the template, for our case none. The following screen is a result of clicking “Next” and allows you to fill in info that will be displayed on the add new item dialog.
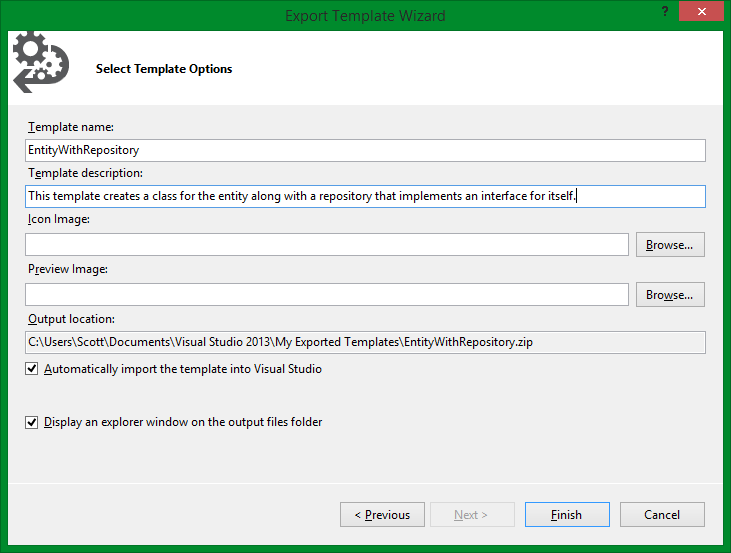
As you can see there are several options like including an icon, output directory and if you want it imported automatically. We are going to have to manually edit a few things and re-import anyway. The output of this the export is a .zip file that contains all the files needed. Unzip this folder and add any template files that are missing. Next edit the MyTemplate.vstemplate file to include the missing files that you just copied into this folder. Use the existing ProjectItem node as a reference and change the file names accordingly.
<VSTemplate Version="3.0.0" xmlns="http://schemas.microsoft.com/developer/vstemplate/2005" Type="Item">
<TemplateData>
<DefaultName>EntityWithRepository.cs</DefaultName>
<Name>EntityWithRepository</Name>
<Description>This template creates a class for the entity along with a repository that implements an interface for itself.</Description>
<ProjectType>CSharp</ProjectType>
<SortOrder>10</SortOrder>
<Icon>__TemplateIcon.ico</Icon>
</TemplateData>
<TemplateContent>
<References />
<ProjectItem SubType="Code" TargetFileName="$fileinputname$Repository.cs" ReplaceParameters="true">Repository.cs</ProjectItem>
<ProjectItem SubType="Code" TargetFileName="$fileinputname$.cs" ReplaceParameters="true">Class.cs</ProjectItem>
</TemplateContent>
</VSTemplate>
You can see that the new file names will be the one input on the add new item dialog and the Repository word will be appended for the repository file. Next just zip up the new contents. (A word of caution, clicking on the parent folder and using “Send To->Compressed Folder” adds an extra folder in between which will not work. I selected all the files and then zipped those up instead.) Now all you need to do is replace the originally created .zip file with the new one at “C:\Users\<Your User Name>\Documents\Visual Studio 2013\Templates\ItemTemplates”, this is where Visual Studio will look for custom item templates. Now you should be able to use your new item template. (Visual Studio may need to be restarted to show up.)

Using the new item template will yield two shinny new files using the name you specified!
But Wait, There’s More
There are also Project Templates that you can create that will give you tons of different files, make sure you have all the right references and even create multiple projects. So for example if you always create an MVC project, import your favorite assemblies, use a certain folder structure, have an additional model, data access, or test projects, you can!
So now you are thinking, this all sounds great, but that sounds like a ton of work, isn’t there some pre-made stuff? The answer of course is yes! John Papa and others maintain an open project called SideWaffle which contains all kinds of commonly used project and item templates that can either work for you or start as a basis for your own modifications.
Let me know in the comments or on twitter @ScottKerlagon about templates you use to save time or ideas on new templates!